Author: Brian A. Ree
0: Tensorflow Linear Regression Loading Data: Intro
Hello, welcome to our tensorflow linear regression tutorial. In this tutorial you will learn how to load stock data from a CSV file
into local data structures for feature development and eventually a linear regression model in tensorflow. For this tutorial you should
have PyCharm setup on your computer. PyCharm is a python IDE that has a free community edition and is a great all around IDE. You can download
and install the IDE from here. Follow the simple setup instructions
and load up our StockWorm project. Now you're ready to go.
1: Tensorflow Linear Regression Loading Data: Data Structures
So first thing's first, I'm not a procedural language coder, and I like my curly brackets. So I decided to end all my python blocks
of code with comments that make me feel warm and fuzzy inside like the curly brackets would have. A primary focus of tensorflow is to provide
machine learning APIs to the masses but in order to start crunching numbers we're going to need some data. Settings up a database and populating it
with stock pricing data is a bit beyond the scope of this tutorial but I can show you how to load up CSV files into python data structures, shall we?
But before I dive into that here is the general process we'll be creating in this tutorial.
- Load CSV data into local data structures.
- Generate or pinpoint features we want to use tensorflow to analyze for us.
- Convert our python data structures in tnesors.
- Push our tensors into a linear regression model.
- Train and evaluate the model.
So let's dive right in. First up we'll create a generic object that is capable of holding different types of data from CSV files.
I don't want to have to recode a lot to introduce new data types so we're going to focus on abstracting certain parts of this process
so that the process can remain general. Ideally I'd like to have one and only one specific class associated with the source data.
The rest of the linear regression model should be plug and play. This is an advanced tutorial so I'm going to assume certain python coding
constructs are familiar or that you know where to look them up. First up our DataRow class.
import sys
import os
class DataRow:
""" A class for holding generic CSV data. """
# Base variables
colData = {}
colName2Idx = {}
colIdx2Name = {}
id = -1
NEXT_ID = 0
# Internal variables
error = False
verbose = False
ignoreError = False
def __init__(self, lVerbose=False, lIgnoreError=False):
self.verbose = lVerbose
self.ignoreError = lIgnoreError
# edef
def copy(self):
r = DataRow()
r.verbose = self.verbose
r.id = self.id
r.colData = copy.copy(self.colData)
r.colName2Idx = copy.copy(self.colName2Idx)
r.colIdx2Name = copy.copy(self.colIdx2Name)
return r
#def
def stampId(self):
self.id = DataRow.NEXT_ID
DataRow.NEXT_ID += 1
# edef
def printDataRow(self):
for key in self.colData:
print("%s: %s" % (key, self.colData[key]['value']))
# efl
print("---------------------")
# edef
def toRow(self):
csvRow = ''
for key in self.colData:
csvRow += self.colData[key]['value'] + ","
# efl
csvRow = csvRow[:-1]
csvRow += os.linesep
return csvRow
# edef
def fromRow(self, csvRow):
cols = csvRow.strip().split(',')
colnum = 0
for col in cols:
self.setMember(colnum, col)
colnum += 1
# efl
# edef
def setMember(self, name, idx, val):
try:
self.colIdx2Name[idx] = name
self.colName2Idx[name] = idx
self.colData[name] = {'value': val, 'idx': idx}
return True
except:
if self.ignoreError == False:
self.error = True
# eif
if self.verbose:
print("Error setting member with index: ", idx, " with value: ", val)
print("Unexpected error:", sys.exc_info()[0])
# eif
# etry
return False
# edef
def getMemberByIdx(self, idx):
return self.colData[self.colIdx2Name[idx]]
# edef
def getMemberByName(self, name):
return self.colData[name]
# edef
# eclass
Let's review our class variables first.
- colData: A dictionary for holding all the column data for this row.
- colName2Idx: A dictionary for converting the column name to the index of that column.
- colIdx2Name: A dictionary for converting the index to the name of that column.
- id: A unique id value for this row of data.
- NEXT_ID: A static value used to keep track of unique ids.
- error: An internal variable that flags whether an exception occured when setting a value in the setMember method.
- verbose: A boolean flag that indicates whether or not verbose logging is turned on.
- ignoreError: A boolean flag that indicates whether or not to ignore any error flags the come up.
Next up is our class methods.
- __init__: Default constructor for the class.
- printDataRow: A custom printing method, I didn't use built in python stuff.
- copy: Creates a new copy of this object with the same data.
- stampId: Used to set a unique id for this data row object, each row gets a unique incrementing id.
- toRow: A simple method for creating a CSV export of this object.
- fromRow: A simple method for importing a CSV export from this class.
- setMember: A general method for setting a class value. The method and class members are data driven from the CSV file headers.
- getMemberByIdx: Returns the value of a member at the given index.
- getMemberByName: Returns the value of a member with the given name.
Take a look at the contructor yourself. It is very simple. We'll review the setMember method first
so that you know how our class data is stored. This will make the accessor methods more intuitive.
def setMember(self, name, idx, val):
try:
self.colIdx2Name[idx] = name
self.colName2Idx[name] = idx
self.colData[name] = {'value': val, 'idx': idx}
return True
except:
if self.ignoreError == False:
self.error = True
# eif
if self.verbose:
print("Error setting member with index: ", idx, " with value: ", val)
print("Unexpected error:", sys.exc_info()[0])
# eif
# etry
return False
# edef
Because we want to be able to support almost any CSV file we use a dynamic way of storing our row information in a local class dictionary.
The setMember method is the way we set our class variables and their values. The name, index of the column, and value are the arguments to the
method. The colData dictionary adds a key with the value of name. It sets the value of that key to a dictionary that contains the value of the column
and the index of the column. I decided to add this layer of abstraction because now we have the ability to add more meta information about each column in our CSV file.
We could potentially add data types, default values, cleaning methods, conversion methods etc to the dictionary.
You'll notice that we also make entries into colName2Idx, and colIdx2Name. These dictionaries make it easy for us to convert between indexes and column names.
We can also lookup each column name iteratively now. THe last thing we want to look at is the exception handling. If there is an issue storing the dictionary values
we can choose to set an error flag. This can then be picked up later in a cleaning or re-evaluation loop. This might not come in handy here but if we start enforcing a data type
conversion the exception handling will certainly come in handy. Let's look at a simple example of accessing our class data.
def getMemberByIdx(self, idx):
return self.colData[self.colIdx2Name[idx]]
# edef
def getMemberByName(self, name):
return self.colData[name]
# edef
The accessor methods are getMemberByIdx and getMemberByName. The let you pull information out of the class with an index or a column name.
See how flexible this is? Sure we could have used the default tensorflow CSV file loader but I wanted to create something dynamic I had complete control over.
We can conect these classes to our own special database or webservice calls furthermore we can control our feature and statistic generation better and can data drive
the way our data is fed into a model and ultimately ran in tensorflow. Trust me it will be awesome. Next up the custom print method.
def printDataRow(self):
for key in self.colData:
print("%s: %s" % (key, self.colData[key]['value']))
# efl
print("---------------------")
# edef
The print data method uses an iterator over the classData dictionary. For each key in the dictionary
the key and value of the key are printed out. Again take a moment to notice how flexible this design is.
def toRow(self):
csvRow = ''
for key in self.colData:
csvRow += self.colData[key]['value'] + ","
# efl
csvRow = csvRow[:-1]
csvRow += os.linesep
return csvRow
# edef
def fromRow(self, csvRow):
cols = csvRow.strip().split(',')
colnum = 0
for col in cols:
self.setMember(colnum, col)
colnum += 1
# efl
# edef
Last but not least are our little helper methods toRow, and fromRow.
We are going to use these methods to create a CSV export of loaded data rows. So that takes care of our
DataRow class. Next up we're going to take a look at a mapping class Data2DataRow. This is another layer in our
abstraction/generalization technique. The mapping between CSV columns and our DataRow class data is defined here.
2: Tensorflow Linear Regression Loading Data: Abstraction Layers
#use -1 to ignore loading a column
mapping = {
"google_price":
{
"Date": "0",
"Open": "1",
"Close": "2",
"High": "3",
"Low": "4",
"Volume": "5",
"Symbol": "6"
},
"weight_age":
{
"Weight": "0",
"Age": "1",
"BloodFat": "2"
},
}
The Data2DataRow class holds a dictionary with mappings that are associated with types of CSV files.
The CSV column and column index are listed here and used to load data into instances of the DataRow class.
Again notice how flexible the design is, we can switch which loading technique we need by changing our index.
That brings us to our next topic the execution dictionary we use to drive the entire process.
The dictionary has keys for classes you haven't seen yet but we're going to review the ones we will use and it'll help you understand
the CSV loading step and the way the software is configured.
"goog_lin_reg_avg100day":
{
'type': 'csv',
'data_2_datarow_type': 'google_price',
'datarow_2_tensor_type': 'goog_lin_reg_avg100day',
'version': '1.0',
'reset': False,
'checkpoint': False,
'limitLoad': False,
'cleanData': True,
'verbose': False,
'rowLimit': 25,
'validatePrct': 0.30,
'trainPrct': 0.70,
'randomSeed': False,
'trainStepsMultiplier': 5,
'learning_rate': 0.000000001,
'log_reg_positive_result': 0.00,
'lin_reg_positive_result': 0.50,
'model_type': 'linear_regression',
'loader': 'load_csv_data',
'files': {
'file1': {'name': dataDir + "/spy.csv.xls", 'appendCols': [{'Symbol': 'spy', 'idx': '6'}]},
'file2': {'name': dataDir + "/voo.csv.xls", 'appendCols': [{'Symbol': 'voo', 'idx': '6'}]},
'file3': {'name': dataDir + "/ivv.csv.xls", 'appendCols': [{'Symbol': 'ivv', 'idx': '6'}]},
}
},
The execution dictionary is the main definition of how we're going to execute our linear regression model. Read over the following list of entries and what they are for
carefully. You'll see how these values drive the next few classes we look at.
- type: The type of data we're going to be loading. This vlaue is checked in the LoadCsvData class along with a version number. This helps us support different
versions of CSV file format from the same source.
- data_2_datarow_type: This represents the Data2DataRow entry that is used to load data from the CSV file into our DataRow class.
- version: The version of the type of data we're loading. Corresponds with the type entry listed above.
- reset: A flag indicating if the LoadCsvData classes data storage should be reset and cleared.
- checkpoint: A flag that turns on checkpoint control during the training process.
- limitLoad: A flag that limits the loaded amount of data to the number of rows specified in the row limit entry.
- cleanData: A flag that turns on data cleaning. That is if any error flag is set in the data rows those rows are then removed.
- verbose: A flag that turns on optional debug logging.
- rowLimit: The maximum number of rows to load when the limitLoad flag is set to true.
- validatePrct: The percentage of the data set to use for the validation process.
- trainPrct: The percentage of the data set to use for the training process.
- trainStepsMultiplier: The number of training steps is set to the number of rows found in the training data set. This field multiplies that amount by the number stored here.
- learningRate: The rate at which the model is trained.
- log_reg_positive_result: The percentage value that indicates a logistic regression model positive result.
- lin_reg_positive_result: The percentage value that indicates a linear regression model positive result.
- loader: The loader to use when loading files for this model. Allows use to specify custom loaders if our default CSV loader doesn't do the trick.
- files: The files to load to provide data for this model.
It all should appear pretty straight forward once you look at the description of each entry. If you can't see it we're defining all the variables and information we need
to run a linear regression model on a set of data. This is part of our abstraction design, to separate the data from it's use by adding manipulation layers that are designed
to be general in nature. In this way we're designing a very flexible tensorflow linear regression model engine. One thing that may have stood out to you is the appendCols
field in the file entries. This little gem allows us to add columns and data on the fly to each row of our imported file. In this case we're using it to add a column, Symbol, to
the imported stock data. The idx entry in this little object is used to set the index value for that column, this value should match properly the Data2DataRow entry and
any other appended columns. That brings us to our data loading process.
3: Tensorflow Linear Regression Loading Data: Loading CSV Data
import csv
import DataRow
import codecs
import sys
class LoadCsvData:
""" A class for loading csv data into a data row. """
rows = []
rowCount = 0
limitLoad = True
rowLimit = 25
cleanData = False
cleanCount = 0
verbose = False
def __init__(self, lRows=[], lLimitLoad=False, lRowLimit=-1, lCleanData=False, lVerbose=False):
self.rows = lRows
self.limitLoad = lLimitLoad
self.rowLimit = lRowLimit
self.cleanData = lCleanData
self.verbose = lVerbose
#edef
def loadData(self, csvFile='', type='csv', version='1.0', reset=False, dataMap={}, appendCols={}):
print ("")
print ("")
print("Loading Data: " + csvFile + " Type: " + type + " Version: " + version + " Reset: " + str(reset))
if self.verbose:
print "Found data mapping:"
for i in dataMap:
print(i, dataMap[i])
#efl
#eif
if self.verbose:
print "Found append cols mapping:"
for i in appendCols:
print(i)
#efl
#eif
if reset == True:
print "Resetting rows:"
self.resetRows()
#eif
if type == 'csv' and version == '1.0' and csvFile != '':
ifile = codecs.open(csvFile, 'rb', encoding="utf-8-sig")
reader = csv.reader(ifile)
lrows = []
rownum = 0
for row in reader:
if rownum == 0:
header = row
rownum += 1
else:
colnum = 0
dRow = DataRow.DataRow()
dRow.verbose = self.verbose
# Append static values outside of the csv like stock symbol etc
for entry in appendCols:
for key in entry:
dRow.setMember(key, str(entry['idx']), entry[key])
# efl
# efl
if self.verbose:
print ('')
# eif
for col in row:
if self.verbose:
print (' %-8s: %s' % (header[colnum], col))
#eif
colName = header[colnum]
if len(dataMap) > 0:
try:
memberIdx = dataMap[colName]
if int(memberIdx) != -1:
dRow.setMember(colName, int(memberIdx), col)
# eif
except:
if self.verbose:
print ("Error setting member with index: ", colnum, " with value: ", col)
print ("Unexpected error:", sys.exc_info()[0])
# eif
# etry
else:
dRow.setMember(colName, colnum, col)
# eif
colnum += 1
# efl
if self.verbose:
if self.limitLoad:
dRow.printDataRow()
# eif
# eif
dRow.stampId()
lrows.append(dRow.copy())
rownum += 1
self.rowCount += 1
#eif
if self.limitLoad == True and self.rowCount >= self.rowLimit and self.rowLimit > 0:
break;
#eif
#efl
ifile.close()
print ("Loaded %i rows from this data file." % (rownum))
lrows = self.sortRows(lrows)
self.cleanRows(lrows)
self.rows.extend(lrows)
print ('CleanCount: %i RowCount: %i RowsFound: %i' % (self.cleanCount, self.rowCount, len(self.rows)))
# eif
# edef
def resetRows(self):
self.rows = []
self.rowCount = 0
self.cleanCount = 0
# edef
def sortRows(self, lrows):
return sorted(lrows, key=id)
# edef
def cleanRows(self, lrows):
if self.cleanData == True:
print ("Cleaning row data...")
should_restart = True
while should_restart:
should_restart = False
for row in lrows:
if row.error == True:
lrows.remove(row)
self.rowCount -= 1
self.cleanCount += 1
should_restart = True
# eif
# efl
# fwl
# eif
# edef
# eclass
Let's take a look at our class variables first.
- rows: The row storage data structure, this objects contains a list of DataRow objects.
- rowCount: The number of rows loaded into the row data structure.
- limitLoad: A flag that limits the number of rows loaded to the rowLimit.
- rowLimit: The number of rows to load when the limitLoad flag is toggled.
- cleanData: A flag that toggles the clean data check.
- cleanCount: The number of rows that were cleaned from this data import.
- verbose: A flag that toggles verbose debug logging.
Taking a quick look at the constructor __init__ you can see that it takes arguments lRows, lLimitLoad, lRowLimit, lCleanData, lVerbose.
Thinking about our execution dictionary? Well you should be! Just kidding. So we can kind of guess that the values in our execution dictionary
are getting passed into the constructor. It's pretty straight forward so we'll move on to our supports methods.
def resetRows(self):
self.rows = []
self.rowCount = 0
self.cleanCount = 0
# edef
def sortRows(self, lrows):
return sorted(lrows, key=id)
# edef
def cleanRows(self, lrows):
if self.cleanData == True:
print ("Cleaning row data...")
should_restart = True
while should_restart:
should_restart = False
for row in lrows:
if row.error == True:
lrows.remove(row)
self.rowCount -= 1
self.cleanCount += 1
should_restart = True
# eif
# efl
# fwl
# eif
# edef
You can quickly see that the resetRows method clears all the data storage and data count values. The cleanRows method will loop over the loaded data
and remove any rows that have the error flag set. Short and sweet, let's see how the data from our CSV file actually gets loaded.
def loadData(self, csvFile='', type='csv', version='1.0', reset=False, dataMap={}, appendCols={}):
print ("")
print ("")
print("Loading Data: " + csvFile + " Type: " + type + " Version: " + version + " Reset: " + str(reset))
if self.verbose:
print "Found data mapping:"
for i in dataMap:
print(i, dataMap[i])
#efl
#eif
if self.verbose:
print "Found append cols mapping:"
for i in appendCols:
print(i)
#efl
#eif
if reset == True:
print "Resetting rows:"
self.resetRows()
#eif
if type == 'csv' and version == '1.0' and csvFile != '':
ifile = codecs.open(csvFile, 'rb', encoding="utf-8-sig")
reader = csv.reader(ifile)
lrows = []
rownum = 0
for row in reader:
if rownum == 0:
header = row
rownum += 1
else:
colnum = 0
dRow = DataRow.DataRow()
dRow.verbose = self.verbose
# Append static values outside of the csv like stock symbol etc
for entry in appendCols:
for key in entry:
dRow.setMember(key, str(entry['idx']), entry[key])
# efl
# efl
if self.verbose:
print ('')
# eif
for col in row:
if self.verbose:
print (' %-8s: %s' % (header[colnum], col))
#eif
colName = header[colnum]
if len(dataMap) > 0:
try:
memberIdx = dataMap[colName]
if int(memberIdx) != -1:
dRow.setMember(colName, int(memberIdx), col)
# eif
except:
if self.verbose:
print ("Error setting member with index: ", colnum, " with value: ", col)
print ("Unexpected error:", sys.exc_info()[0])
# eif
# etry
else:
dRow.setMember(colName, colnum, col)
# eif
colnum += 1
# efl
if self.verbose:
if self.limitLoad:
dRow.printDataRow()
# eif
# eif
dRow.stampId()
lrows.append(dRow.copy())
rownum += 1
self.rowCount += 1
#eif
if self.limitLoad == True and self.rowCount >= self.rowLimit and self.rowLimit > 0:
break;
#eif
#efl
ifile.close()
print ("Loaded %i rows from this data file." % (rownum))
lrows = self.sortRows(lrows)
self.cleanRows(lrows)
self.rows.extend(lrows)
print ('CleanCount: %i RowCount: %i RowsFound: %i' % (self.cleanCount, self.rowCount, len(self.rows)))
# eif
# edef
Let's knock out the first few blocks of code and get into the real stuff.
print ("")
print ("")
print("Loading Data: " + csvFile + " Type: " + type + " Version: " + version + " Reset: " + str(reset))
if self.verbose:
print "Found data mapping:"
for i in dataMap:
print(i, dataMap[i])
#efl
#eif
if self.verbose:
print "Found append cols mapping:"
for i in appendCols:
print(i)
#efl
#eif
if reset == True:
print "Resetting rows:"
self.resetRows()
#eif
First off we do a little logging on the configuration of our file load.
This is really useful when you're running models because you can see if you have a data issue right away. Now if the verbose flag is set to true,
we print out the keys and values of our data mapping. We also print out the entries found in the appendCols dictionary. And last but not least if the
reset flag is set then we will reset all our row counts and row storage lists before we load new data. The start of the file loading loop is up next.
if type == 'csv' and version == '1.0' and csvFile != '':
ifile = codecs.open(csvFile, 'rb', encoding="utf-8-sig")
reader = csv.reader(ifile)
lrows = []
rownum = 0
for row in reader:
if rownum == 0:
header = row
rownum += 1
else:
We check to see if this is the correct type and version, this allows use ot add new types and versions in the future if we need to deal with different file formats or CSV formats.
A file handle is opened up and then a CSV reader is created. This takes care of the complexities of reading CSV files for us. We reset our local data storage list and row count variable.
We are expecting a header row so the first row is loaded into a local header variable. Notice our append and isHeader variables are set to false on each new loop iteration.
Next we'll look into the data loading code.
else:
colnum = 0
dRow = DataRow.DataRow()
dRow.verbose = self.verbose
# Append static values outside of the csv like stock symbol etc
for entry in appendCols:
for key in entry:
dRow.setMember(key, str(entry['idx']), entry[key])
# efl
# efl
if self.verbose:
print ('')
# eif
for col in row:
if self.verbose:
print (' %-8s: %s' % (header[colnum], col))
#eif
colName = header[colnum]
if len(dataMap) > 0:
try:
memberIdx = dataMap[colName]
if int(memberIdx) != -1:
dRow.setMember(colName, int(memberIdx), col)
# eif
except:
if self.verbose:
print ("Error setting member with index: ", colnum, " with value: ", col)
print ("Unexpected error:", sys.exc_info()[0])
# eif
# etry
else:
dRow.setMember(colName, colnum, col)
# eif
colnum += 1
# efl
if self.verbose:
if self.limitLoad:
dRow.printDataRow()
# eif
# eif
dRow.stampId()
lrows.append(dRow.copy())
rownum += 1
self.rowCount += 1
#eif
In the else clause we are dealing with data rows, not header rows, so this is where the main processing of information occurs. The first thing we do
is reset our local variables. If you're been thinking inner loop, you're right. We're going to be looping over the columns in each row and building an
instance of our DataRow class that we'll store in our local data list. The first thing we do is process the appendCols parameter. This is a list of
dictionary objects that contain a column name, a column value, and an index. It is to provide global values to the rows that are being loaded. For instance you could
pass in the file name, the date, the symbol the data is for, etc. Take a close look and you'll see that we're using our setMember method that we reviewed earlier.
The process of building our DataRow entry is underway! Now let's loop over the columns and load up that data as well.
for col in row:
if self.verbose:
print (' %-8s: %s' % (header[colnum], col))
#eif
colName = header[colnum]
if len(dataMap) > 0:
try:
memberIdx = dataMap[colName]
if int(memberIdx) != -1:
dRow.setMember(colName, int(memberIdx), col)
# eif
except:
if self.verbose:
print ("Error setting member with index: ", colnum, " with value: ", col)
print ("Unexpected error:", sys.exc_info()[0])
# eif
# etry
else:
dRow.setMember(colName, colnum, col)
# eif
colnum += 1
# efl
If the verbose flag is toggles we'll get a print out of each column name and it's value. I would only recommend doing this if the limitLoad flag and
rowLimit max have been set. The column name is stored, we get this from the header row we picked up on row number zero. If we have a data mapping to use the we use it.
If not we just use the column name and the column number and pass in the column value to set member. This would be considered almost an automapping. For the case when we do
have mapping info we pull the index we want from the data map, we check if it is a column we want to ignore (-1 index number). If it is not we call set member with the column name,
the column index from our mapping, and the column value. Last but not least if you look back a few code sample you'll notice at the end of our data loading loop is a special
logging call that is only run if both verbose and limiLoad are set to true, this prints out a string represetation of each row of data loaded. Not a good idea if you plan
to load a lot of data.
4: Tensorflow Linear Regression Loading Data: Conclusions
That brings us to the conclusion of our data loading tutorial. There are a few more lines of code that are used to append the new DataRow object to a local data list.
Loop variables control header detection and row appending. Once outside of the main processing loop the file accessors are closed and the local data row list is appended to our
class member data row list. Bam! You're sooo close to running a simple neural network linear regression model in tensorflow. In the next tutorial we'll see how to generate features on
our data, think statistics and things we want tensorflow to pay attention to.
def run(exeCfg):
type = exeCfg['type']
data_2_datarow_type = exeCfg['data_2_datarow_type']
datarow_2_tensor_type = exeCfg['datarow_2_tensor_type']
version = exeCfg['version']
reset = exeCfg['reset']
checkpoint = exeCfg['checkpoint']
verbose = exeCfg['verbose']
limitLoad = exeCfg['limitLoad']
rowLimit = exeCfg['rowLimit']
validatePrct = exeCfg['validatePrct']
trainPrct = exeCfg['trainPrct']
randomSeed = exeCfg['randomSeed']
learning_rate = exeCfg['learning_rate']
log_reg_positive_result = exeCfg['log_reg_positive_result']
lin_reg_positive_result = exeCfg['lin_reg_positive_result']
model_type = exeCfg['model_type']
loader = exeCfg['loader']
cleanData = exeCfg['cleanData']
trainStepsMultiplier = exeCfg['trainStepsMultiplier']
dataMap = Data2DataRow.mapping[data_2_datarow_type]
files = exeCfg['files']
data = None
print("Found loader: " + loader)
if loader == 'load_csv_data':
data = LoadCsvData.LoadCsvData()
data.checkpoint = checkpoint
data.limitLoad = limitLoad
data.rowLimit = rowLimit
data.verbose = verbose
for file in files:
csvFileName = files[file]['name']
appendCols = files[file]['appendCols']
data.loadData(csvFileName, type, version, reset, dataMap, appendCols)
# efl
# eif
# edef
Oops, forgot to go over the code that executes our execution configuration object, we went over this earlier in this tutorial.
It's fairly simple we offload all the values in the execution configuration dictionary and the we begin the file loading process.
Global variables are set with the instantiation of the LoadCsvData object. Then for each file listed in the execution configuration's
files entry we load the csv data and pass in the necessary parameters to the loadData method. The parameters are a mixture or local and global
params. Aaaaaaaand that now concludes out tutorial. You can run the tutorial by executing the Main.py file.
To edit your run configurations in PyCharm find the Edit Configurations option under the Run menu.
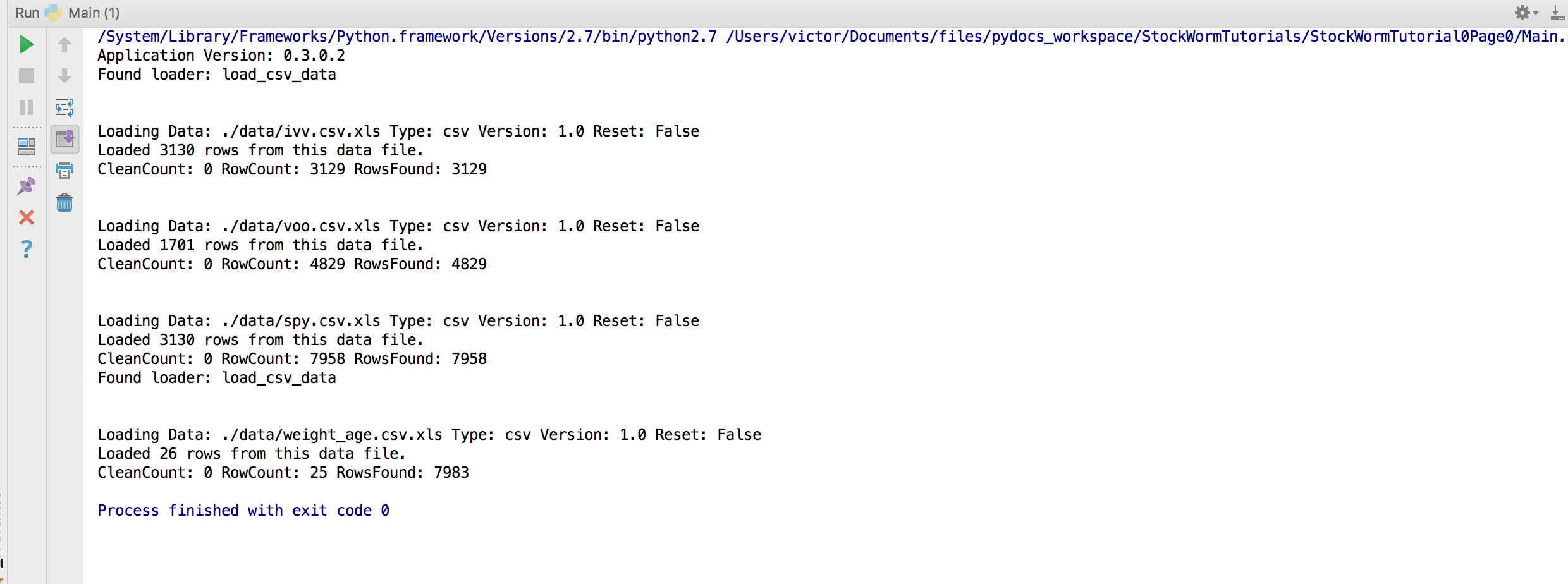
See the picture below.
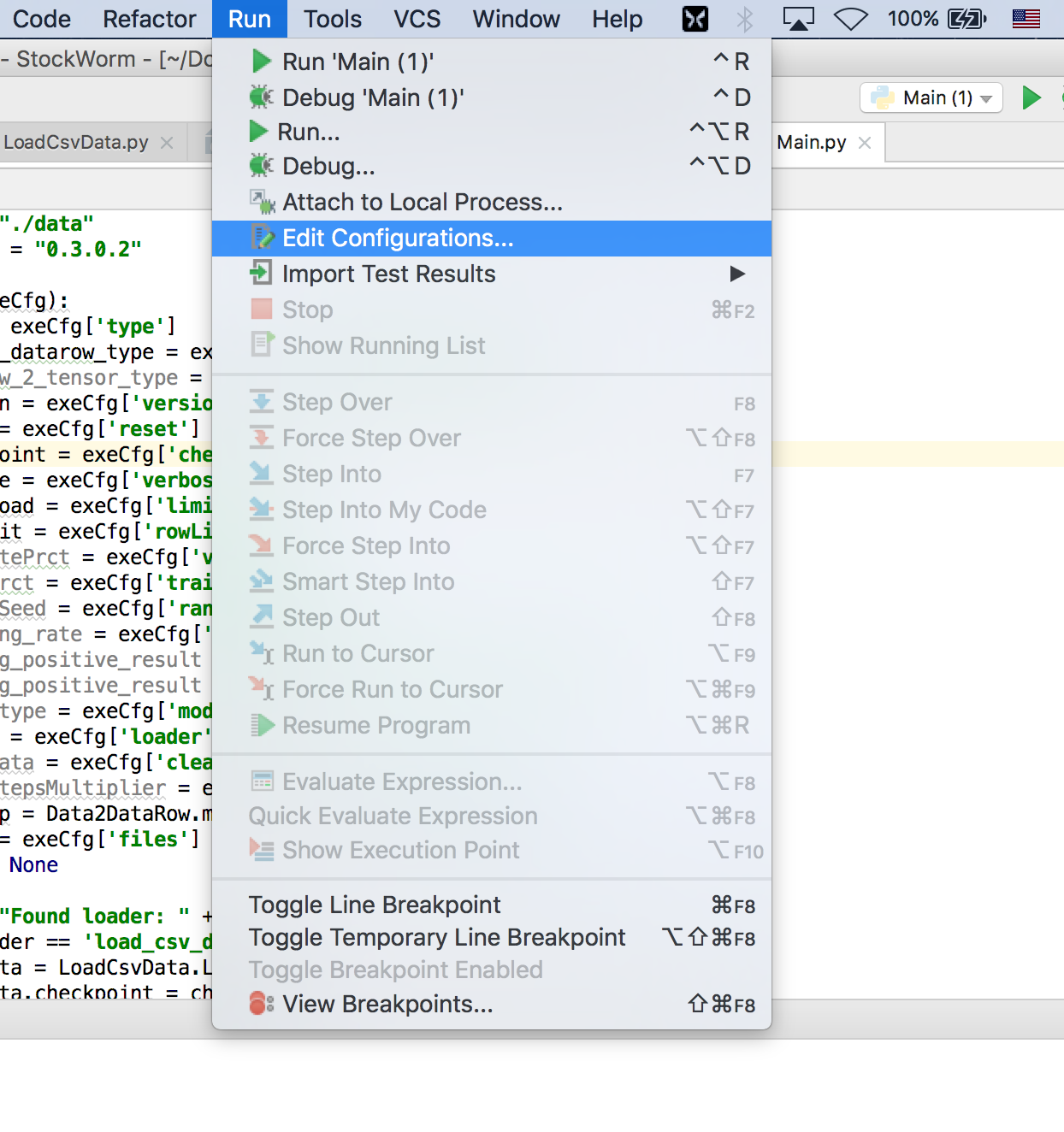
Fill out the information on the project you want to register on the Edit Configurations screen.
See the picture below.
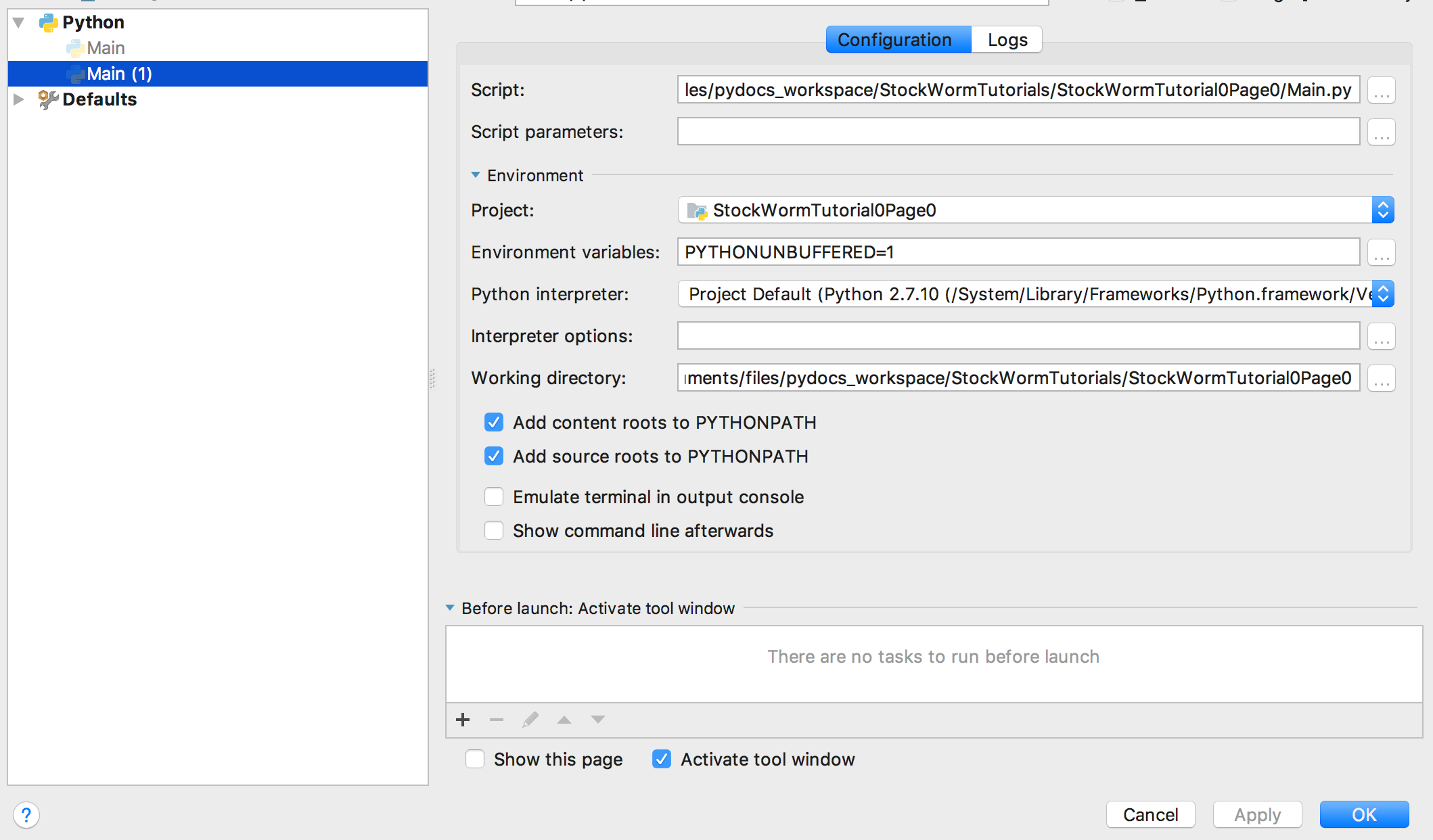
And last but not least you should be able to execute your CSV data loading code and see a print out similar to the one depicted below.